 | ||
|
|
[Background][About the Study Area][Analysis Process][ Suitability Assessment][Home] | |
|
Technical
Model-Building Methodology
The "Arithmetic Overlay"
allows the modeler to combine several input grid themes by
assigning an operator and multiplier to each scheme. The main advantage is that
it allows Boolean manipulation to scale and calculate intersections and overlapping areas. Example: I have two input files "floodplain" and
"riverbanks." We want to know which areas are
To this end, the following values are assigned to specific areas:
If we multiply the values of each grid cell, the result consist of 0s,
1s, and 2s which mean:
Because the output grids of the Arithmetic Overlay are continuous, these had to be converted to discrete grid themes using the Reclassification function. The Reclassification Process allows you to group cell values into classes. Classes are defined by specifying the values each class will contain. The input data for the reclassification is a grid theme. The output theme is a grid theme containing the newly defined classes. Once all the grid themes were complete, they were connected to a Weighted Overlay. The Weighted Overlay Process allows you to combine data from
several input grid themes by converting their cell values to a common scale,
assigning a weight (percent influence) to each theme, and giving a weighted
value to each attribute considered. Each category in the grid themes used in the models was assigned a numerical value, or "influence value," ranging from 0 to 100 according to criteria established by the team. By assigning a value to each category, one translates its degree of importance to a format that the computer software can use to run a model. Categories with high values are given a high degree of importance, while categories with low values are given low importance. These values were assigned to each theme category with the Weighted Overlay function of the ModelBuilder. In addition to establishing a value for each category, each variable (grid theme) considered in the model was assigned a percent value to reflect its degree of influence in the model. To run the model, all values must add up to 100. The variables that influence the model the most are given the highest percentage. Once the connections to the Weighted Overlay were established, the models were run to produce shapefiles showing zones of varying suitability for human settlement, agriculture and preservation. Notes: What does this difference mean? The results for both approaches are the same, as long as the model is only applied to the property area. As soon as the model would, for whatever reason, be extended, let's say to include adjacent properties, one would have to produce a shapefile similar to those used for the settlement or preservation models. This modified process also seemed to reveal an error in the
ModelBuilder program. When the model is saved under a different name, the
program sets back all the "Restricted" values to zero. If the "NO
DATA" area has been set to "Restricted" (meaning that the area is
taken out of the weighing process completely and left blank) it must be re-set
to this value after saving it under another name. ____
|
|
Algorithmic Flowchart: Agricultural Suitability Model |
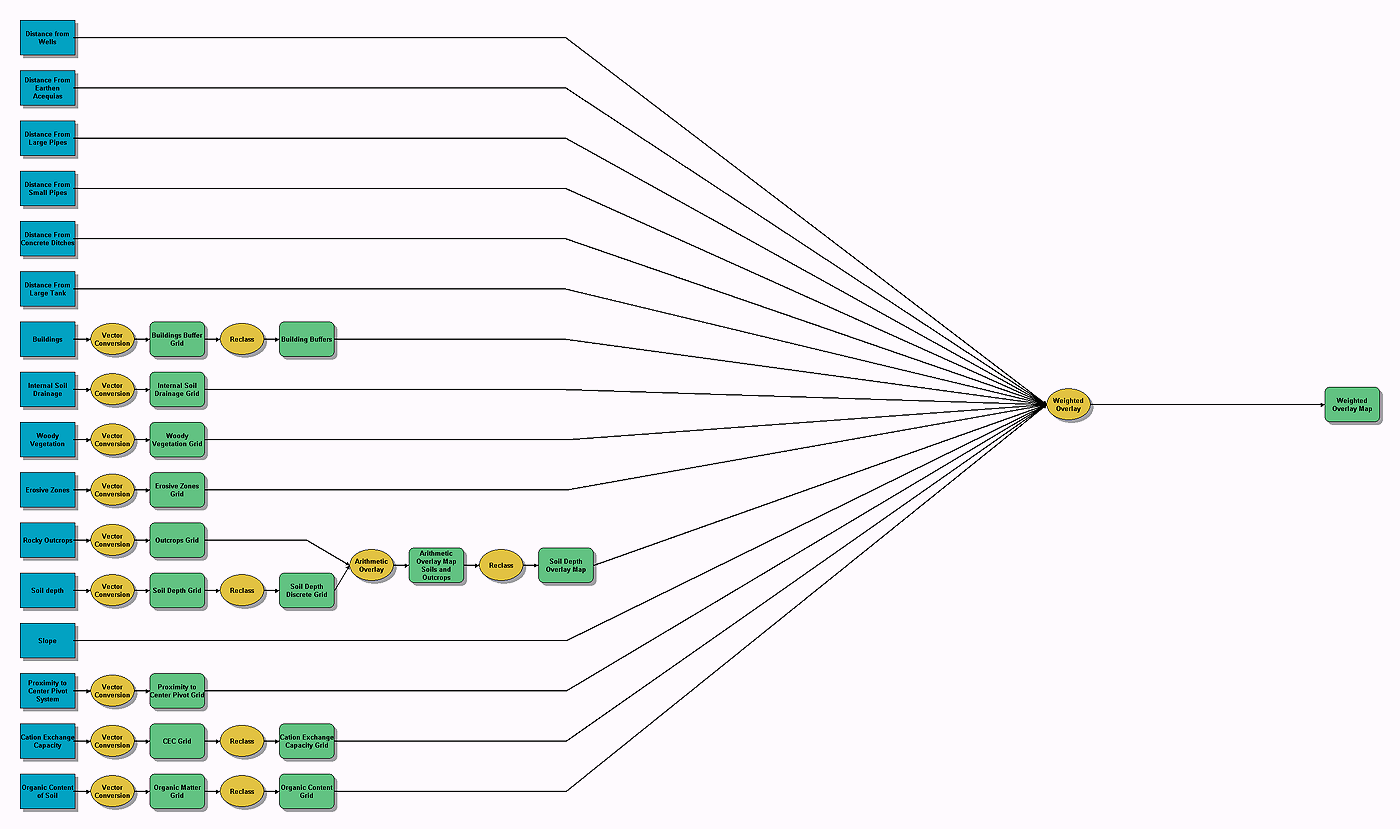
|
Algorithmic Flowchart: Human Settlement Suitability Model |

|
Algorithmic Flowchart: Preservation Suitability Model |

|
Return to |